

Where’s my Data?
There is a battle today inside IT to meet Enterprise Data Warehouse (EDW) overnight data load commitments with ETL solutions. Traditional ETL solutions have struggled to keep pace with the tsunami of data now being generated. Fortunately, there is a solution with an ecosystem of software called Hadoop. Before I stage the problem, I want to give you a reason to care.
Hadoop’s benefits:
- Process more data in a smaller batch window to meet ETL and EDW commitments
- Reduce EDW storage costs
- Eliminate the need to purge EDW data or archive to tape
- Improve the query performance of the EDW
- Free up enterprise grade servers for business intelligence and analytics use
Financial Justification
IT leaders are justifying a Hadoop deployment on the savings from reduced EDW storage fees and extra server capacity. The real benefit comes from their ability to meet or exceed ETL commitments.
What is ETL?
ETL stands for Extract, Transform, and Load. There is a high demand inside every business for enterprise data to facilitate decision making and report on recent performance (see Take Action … and Empowering Business Leaders …). Transactional data produced at the point of sale or within production facilities exists in many different systems, types, structures, and generally in a highly normalized form. Thus, this data in its original state is difficult to use for reporting and analytics until it is extracted from its source system, transformed into a denormalized, consumable format and structure and loaded into a central repository known as an Enterprise Data Warehouse (EDW). The ETL process is the facilitator.
ETL Process

Enterprise Data Warehouse
Enterprise data warehouses (EDW) provide a centralized source for enterprise data. This data can be consumed by business intelligence tools because it exists in a known format and structure and represents a known point in time (i.e., performance data as of 11:55PM the previous day).
An EDW receives the data from an enterprise data integration hub in nightly batch loads supported by the ETL process. During these batch loads, the EDW is not accessible.
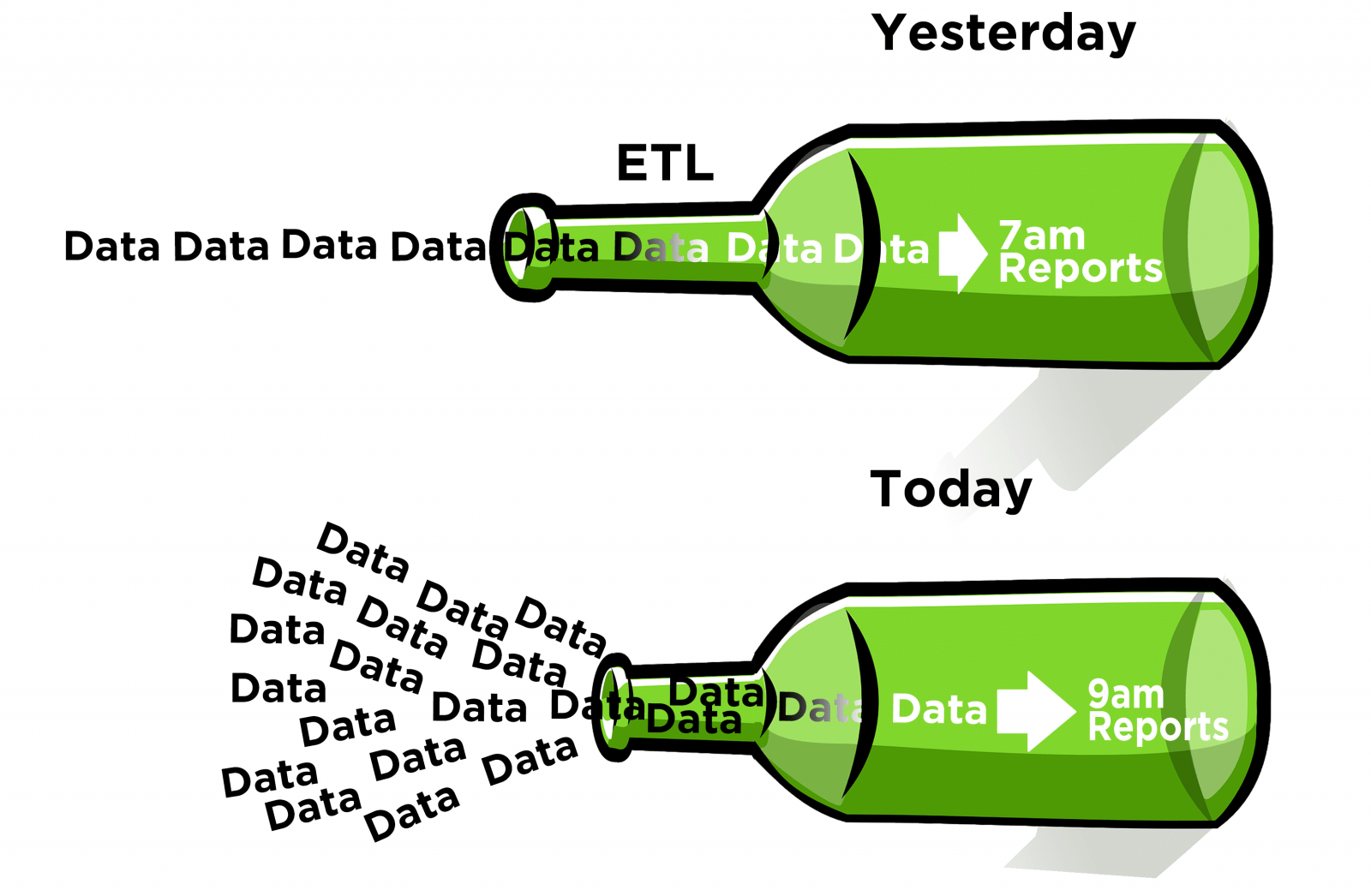
The Bottleneck: More Data Through a Shorter Processing Window
The ETL process has been deployed in enterprises for decades. Today there are two realities that have created a nightly bottleneck of data, delaying the availability of reports to analysts the next morning. First, the global economy. Businesses of all sizes are selling in multiple time zones, thereby shrinking the window of time available to the ETL process. Second, the amount of data available to be processed has exponentially increased and will continue to increase going forward (see IoT Tsunami).
More data must now be pushed through a shorter processing window of time.

Offload ETL with The Hadoop Ecosystem
Apache Hadoop is “a framework that allows for the distributed processing of large data sets across clusters of commodity computers using simple programming models.” Hadoop has been proven to be capable of offloading the heavy ETL jobs and finish them on time.
Using an algorithm called MapReduce, Hadoop breaks the complex operation into smaller and more manageable chunks. It then distributes the chunks to a set of processing nodes (servers) for parallel processing. Hadoop can finish complex batch jobs much faster using this divide and conquer method. The transformed data is then loaded from Hadoop into the enterprise data warehouse. Bottleneck eliminated!
As mentioned, organizations can write MapReduce jobs (mostly Java programs) for data transformation, or they can use SQL like queries leveraging HiveQL or scripts (Pig script) to get the same results. Alternatively, these organizations can explore the power of the broader Hadoop ecosystem and the specialized tools available for ETL efforts:
-
- Sqoop: Apache Sqoop(TM) is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured data stores such as relational databases (ie, EDW).
-
- Flume: Apache Flume is a service for efficiently collecting, aggregating, and moving large amounts of log data into Hadoop.
-
- Nifi: Apache nifi is an easy to use, powerful, and reliable data flow management tool for data routing, transformation, and system mediation logic. The GUI based Drag & Drop type tool makes building complex data flow processes really easy.
- Spark: Apache Spark™ is a data processing framework which is about 100 times faster than MapReduce and therefore a common replacement for MapReduce for large scale data processing.
Free up Enterprise Grade Servers
By offloading the heavy ETL jobs to Hadoop, organizations can use the enterprise grade servers for other business intelligence and analytics uses. They will save time and money and get better value out of their hardware investment.
Offload Data to a Lower Cost Option
Another major inherent challenge with the increase in data collection is what to do with old data. Data warehouses generally do not delete (purge) old data. Purging data from a warehouse may result in the loss of data that would prove to be valuable in years to come (see Apollo 11 missing tapes). The storage size of data warehouses will continue to grow over time as new data flows in from both old sources and new internal or external sources.
Data growth is not a bad thing, as it increases the reporting and analytical capabilities of an organization. But if neglected the data growth can pose a lot of challenges. The cost of data storage increases, the query performance becomes poorer, and the ETL times increase as loading new data to a bigger database takes longer.
Start with Cold Data

Data in a data warehouse is loaded by date and can be categorized in three groups.
-
- Hot data is the most frequently accessed data. Generally, the data entered into the system in last 90 days falls into this category.
-
- Warm data is not so frequently accessed but is still in use for many reports and queries. Data between 90 days and 2 years old is classified as warm data. This data is important for business reports and dashboards.
- Cold data is rarely used. Data older than 2 years generally falls into this category. Businesses rarely use this data for reports, but must keep it in storage for compliance reasons.
Cold data is just sitting there, consuming expensive storage resources without adding value to the business. Data that will rarely be used in reports and is kept only for compliance purposes can be offloaded to magnetic tapes. While these tapes are less expensive, they are difficult to access and do require tremendous care when storing. Anyone who needs to access cold data on tapes would have to go searching for the tape it was stored on and go through a data extraction process with the risk they might come up empty handed as NASA experienced.
A better alternative is to offload cold data to Hadoop storage. Hadoop storage is easy to access and uses comparatively inexpensive commodity hardware to store data. Almost every database vendor now supports SQL on Hadoop, allowing the offloaded data to still be queried if required, therefore eliminating the hunt.
Don’t Wait to Investigate Hadoop
We encourage you to investigate the Hadoop ecosystem if you are experiencing any of the pain points described in this blog:
- Unable to meet ETL and EDW load batch windows
- EDW storage costs are soaring
- Concerned about the ability to find and retrieve anything from tape
- EDW query performance is slower than ever
- You need more enterprise grade server capacity for business intelligence and analytics use
Tell us about your experiences.
About the Author:
Joydeep Misra currently leads the IoT and Big Data initiatives at Bridgera LLC in Raleigh, NC. He is passionate about new technologies and adding value through innovative use of emerging technologies. He is currently responsible for Bridgera’s IoT platform using open source Big Data technologies and Bridgera’s ETL Offload capabilities.


{kind=link}